Announcing the Official Vantage Kubernetes Integration
The Vantage Kubernetes agent provides a single in-cluster deployment that handles both metrics collection and upload to Vantage—without any intermediary requirements.

Today, Vantage announces the launch of a new Kubernetes integration to power Kubernetes cost and efficiency metrics. This agent marks a significant improvement to the existing OpenCost-based integration, with the aim of providing a simpler, cheaper, and more reliable way to ingest cost and usage data from your Kubernetes clusters. This new integration is now the default, recommended method for all customers to onboard new Kubernetes clusters to Vantage.
Before, customers needed to configure OpenCost and Prometheus within their clusters, as well as set up a managed Prometheus in their infrastructure account. This setup introduced significant overhead and operational complexity, as well as incurred additional, non-trivial costs to the customer. The automated deployment within Vantage was also limited to AWS, so users with GCP and Azure Kubernetes deployments had to find alternatives to Amazon Managed Prometheus.
Now, Vantage is offering a single in-cluster deployment that handles both metrics collection and upload to Vantage without any intermediary requirements. Like the existing OpenCost integration, the Vantage Kubernetes agent will collect CPU, RAM, GPU, and volume cost metrics; however, setup will be simpler, requiring only the Vantage Kubernetes agent to be deployed within the cluster using a Vantage API token. The agent will upload the metrics directly to Vantage without the need to deploy any additional infrastructure. Along with being easier to deploy, the agent uses significantly fewer resources and does not require customers to scale the Prometheus pods required by OpenCost to handle the scale of their clusters.
The Kubernetes integration is available to all customers and can be deployed using this Helm chart. If you have an existing integration deployed, head to the documentation to start the migration. If you are starting from scratch, head to the Integrations page to get started.
Frequently Asked Questions
1. What is being launched today?
Vantage is launching the Vantage Kubernetes agent: a Docker container you run in your Kubernetes cluster that will collect metrics and upload them to Vantage without having to manage Prometheus.
2. Does the Vantage Kubernetes agent collect different data than OpenCost?
Yes. Today, the Vantage Kubernetes agent collects the same metrics as the OpenCost agent, along with both Namespace labels and Annotations (optionally enabled) being included in the label list. Namespace labels will be represented with a namespace: prefix, and Annotations will be represented with an annotation: prefix.
3. Will Vantage continue to support OpenCost?
Yes, there is no plan to cease support of OpenCost. Customers can continue to run their existing OpenCost deployments; however, new accounts will only be presented with the Vantage Kubernetes agent deployment option in the UI.
4. Who is the customer?
Any customer who wishes to import and visualize Kubernetes cost and efficiency metrics. This is useful for customers with shared Kubernetes clusters who want to understand which teams or services are contributing the most to shared costs. You can read more about our Kubernetes feature set here.
5. What is required to install the agent?
To get it running, all you need is a Vantage API token. Instructions for generating a token can be found on the Integrations page. Next, you’ll deploy our container in your Kubernetes cluster via this Helm chart.
6. How does the Vantage agent differ from OpenCost?
The Vantage agent depends only on native Kubernetes APIs, primarily the kube-apiserver for metadata and the kubelet resources endpoint for collecting container and node usage data. It manages the periodic collection of data from these sources and storage of them for aggregation, resulting in a significantly simpler setup within the Kubernetes cluster. Data is then exported directly to the Vantage service via an API, using your API token for authentication, avoiding additional storage fees from an intermediary service, like Amazon Managed Service for Prometheus. This architecture also removes the need for customers to deploy OpenCost-specific Prometheus pods, which can be difficult and expensive to scale.
7. How long does it take for Kubernetes costs to be available?
Costs are aggregated and exported hourly and, as before, updated within the Vantage platform nightly. However, costs will not be calculated until the cost data from the cluster’s corresponding infrastructure provider is available. This often takes 48 hours to complete because of delays from the underlying service provider (e.g., AWS) to fully represent costs from this time period.
8. Can I use the Vantage agent with Kubernetes clusters outside of AWS?
Yes, this agent will work in Azure Kubernetes Service (AKS), Google Kubernetes Engine (GKE), as well as Amazon Elastic Kubernetes Service (EKS). As long as the cost data for the underlying cluster instances is available in Vantage, it is possible to calculate the pod costs.
9. What connectivity does the Vantage agent require?
The Vantage Kubernetes Agent requires connectivity to the cluster’s kube-apiserver, the kubelet resources endpoint (generally, port 10250 on a kubelet), the Vantage API, and S3 in us-east-1.
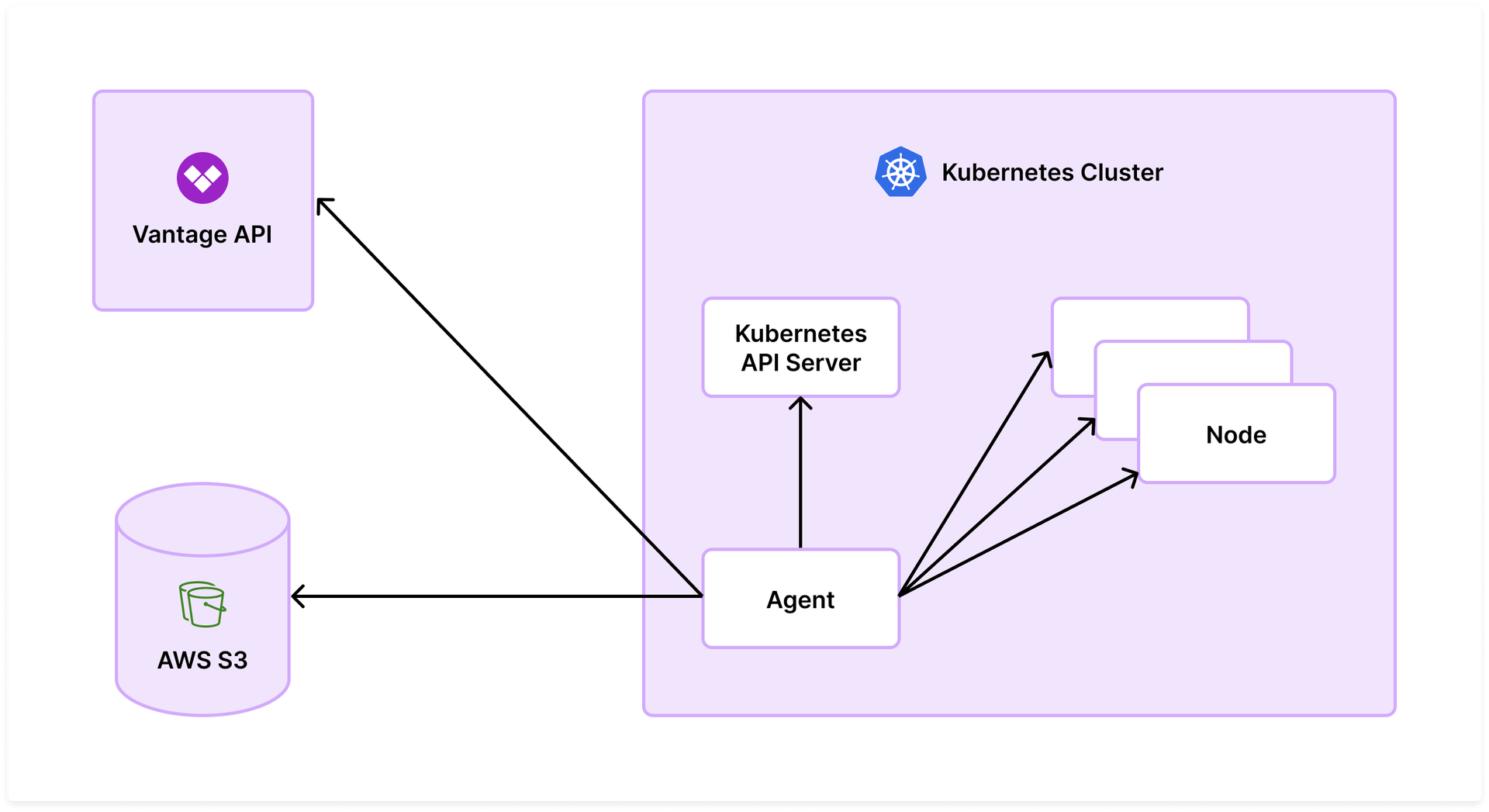
The Vantage Kubernetes agent architecture
10. How does the Vantage agent access the cluster endpoints?
All Kubernetes-related access (kube-apiserver and kubelet) is granted via Kubernetes RBAC using a Service Account and ClusterRole, which are included in the Vantage Kubernetes agent Helm chart and available for auditing.
11. Will I lose data with migrating from OpenCost?
No, you will not lose data. If you are moving from an OpenCost integration to the agent-based integration, you can contact support@vantage.sh to have your previous integration data maintained. Any overlapping data will be removed from the agent data by the Vantage team.
12. How well does the agent scale?
In addition to ease of setup, we have focused on the scalability of the agent to meet the demands of thousand-node-scale Kubernetes clusters. There is a linear resource requirement based on total number of nodes within a cluster, which is approximately 2MB of memory per node within the cluster.
For example, with a 1000-node cluster that has approximately 10 pods per node, we expect the agent to consume ~2GB of memory.
13. Will my previous Kubernetes filters work with the new integration?
Yes, except for cases where labels contained characters that were excluded from Prometheus labels, such as -. The OpenCost integration received the normalized version of those labels from Prometheus. The Vantage agent receives labels directly from the kube-apiserver, meaning they are more accurate but will require updating filters that previously used the normalized values.
You can contact support@vantage.sh to have these filters and data converted for you.
14. Does the Vantage agent support on-premises Kubernetes clusters?
At this time, the agent does not support custom rates for on-premises servers; however, we do plan to add this support in the future. Customers with on-premises clusters that would like to track can still install OpenCost and configure it with custom prices.
15. Does the agent support GovCloud clusters?
By default this should work, but if you have restricted network access, you can contact support@vantage.sh, and we can work with you on GovCloud support.
16. How do I enable collection of Annotations?
The agent accepts a comma-separated list of Annotation keys called VANTAGE_ALLOWED_ANNOTATIONS as an environment variable at startup. If you are using the Helm chart, you would configure the agent.allowedAnnotations parameter of the Helm chart.
17. How do I enable collection of Namespace labels?
The agent accepts VANTAGE_COLLECT_NAMESPACE_LABELS as an environment variable at startup. If you are using the Helm chart, you would configure the agent.collectNamespaceLabels parameter of the Helm chart.
18. Does my Vantage Cost Report experience differ at all from OpenCost?
The Vantage agent adds support for Savings Plan discounts, which can be toggled on and off. Spot pricing will also automatically be accounted for, with no additional work required.
19. What is the reason why the agent needs access to S3?
The agent uses S3 to upload this data to Vantage for processing. The bucket is located in us-east-1.
Sign up for a free trial.
Get started with tracking your cloud costs.
Read more
Vantage Updates Temporal Cloud Integration to Use the Cloud Billing API

Vantage Launches SUM and CASE Statement Billing Rules
Vantage Launches MCP Connectors for the FinOps Agent
Vantage Launches Canvas: An AI-Enabled Business Intelligence Dashboard
