Salesforce to BigQuery ETL with Google Cloud
How we loaded Salesforce data into BigQuery to capture daily snapshots of our sales pipeline.

Over the summer we setup a data pipeline from Salesforce to BigQuery using Google Cloud to capture data about our sales pipeline.

Along the way, we wrote a lot of SQL, incurred excessive cloud costs, and learned a bit about data engineering.
Business Problem: Sales Pipeline Snapshots
Sales and marketing teams depend on a healthy pipeline of deals every quarter to hit their number. But every market has different characteristics in the way that deals get done. Some businesses need a very large pipeline, with deals that take months to develop and can easily slip to another quarter. Others need a smaller pipeline, knowing that many deals that appear during the quarter can close in the same quarter.
It does not really matter what the metrics are, as long as they can be measured and planned for. Several definitions help us get a handle on what the business looks like:
- Pipeline Coverage: The total dollar amount of deals in pipeline divided by the quarterly goal. For example, if there are $30M of deals in pipeline, with a quarterly goal of $10M, then there is 3X coverage.
- Close Rate: The percentage of deals which are "Closed Won" divided by the number of deals which entered the pipeline over the given period.
- Pipeline Created in Quarter: The dollar amount of new deals that entered the pipeline this quarter.
By taking daily snapshots from Salesforce we can capture these metrics as they appeared at the beginning of the quarter and end of quarter. For example, if we began the quarter with 2X coverage and ended with 0.5X coverage and did not hit our sales goal, we can say that a larger pipeline is required for next quarter and thus we should invest more in marketing or sales development.
But to even begin that conversation, we have to have the data.
Salesforce Object Model
What defines a sales pipeline? In Salesforce this is the Opportunity object. An opportunity is a deal, with a projected size, a stage such as "Technical Validation", an Account (company), and other information. What information is relevant to be captured depends on how your Salesforce instance is configured.
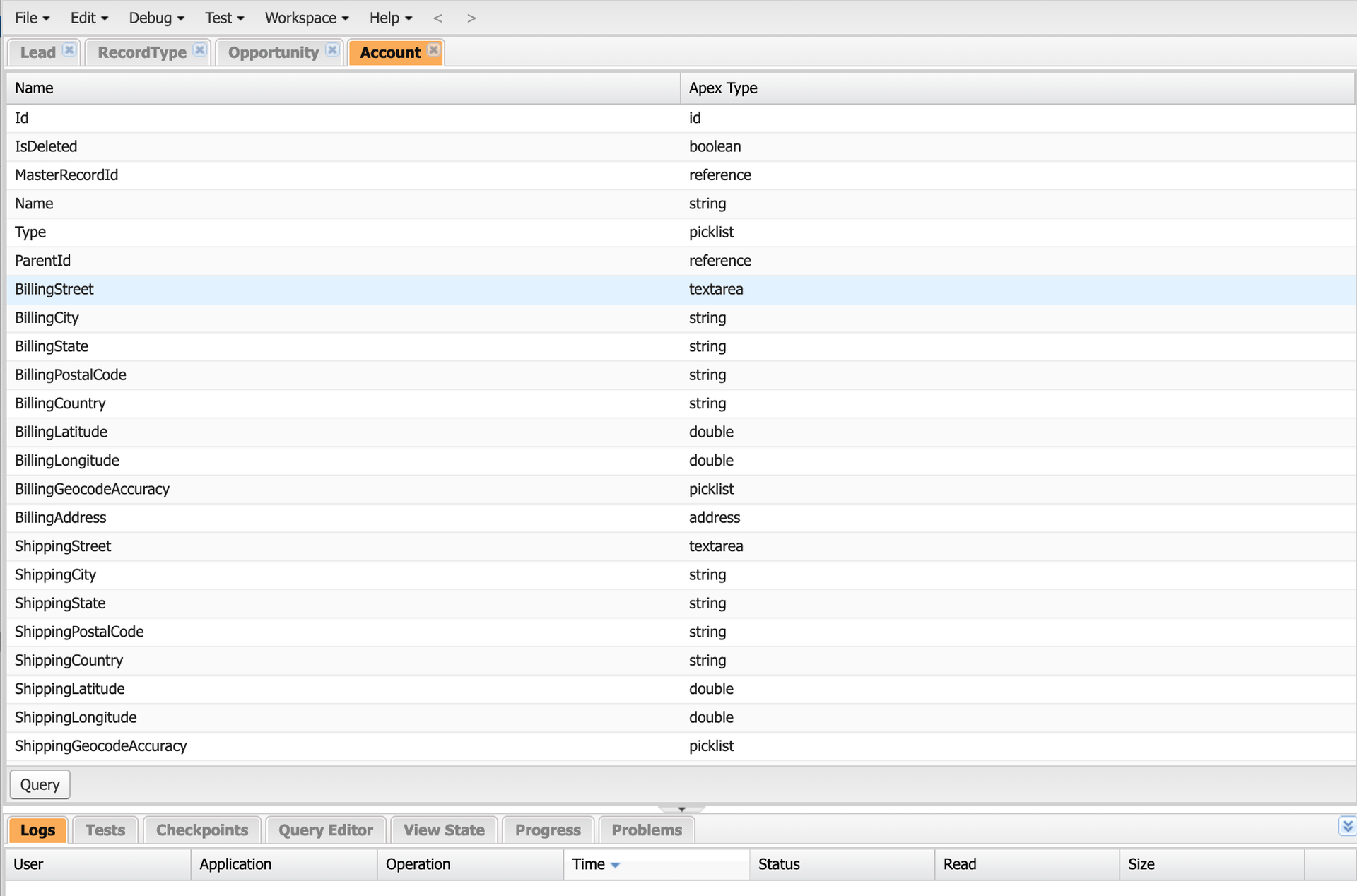
Inspecting objects in our Salesforce instance in the built-in developer console.
Salesforce makes it easy to inspect your data model and the fields defined therein using the developer console shown above. Most teams will customize their instance, adding fields such as Vantage_Acount_ID__c where __c denotes a custom field. As a developer or data engineer, the developer console within Salesforce is very useful for translating business requirements into column names to begin building the ETL solution.
Google Cloud Data Fusion
We had already moved product usage metrics, revenue data, and web analytics to BigQuery and were reaping the benefits. But the only ETL process we had running was configured automatically from Google Analytics to BigQuery. We looked for something that leveraged services already available in Google Cloud.
We came upon CDAP, an Hadoop-based technology which provides connectors to BigQuery and other Google Cloud data products from a variety of external data sources. CDAP now operates as Google Cloud Data Fusion (CDF), a fully managed service.
We followed this recipe for setting up our pipeline, focusing on the "Salesforce Batch Multi Source" plugin. This plugin has a JSON definition file which can be imported into CDF.
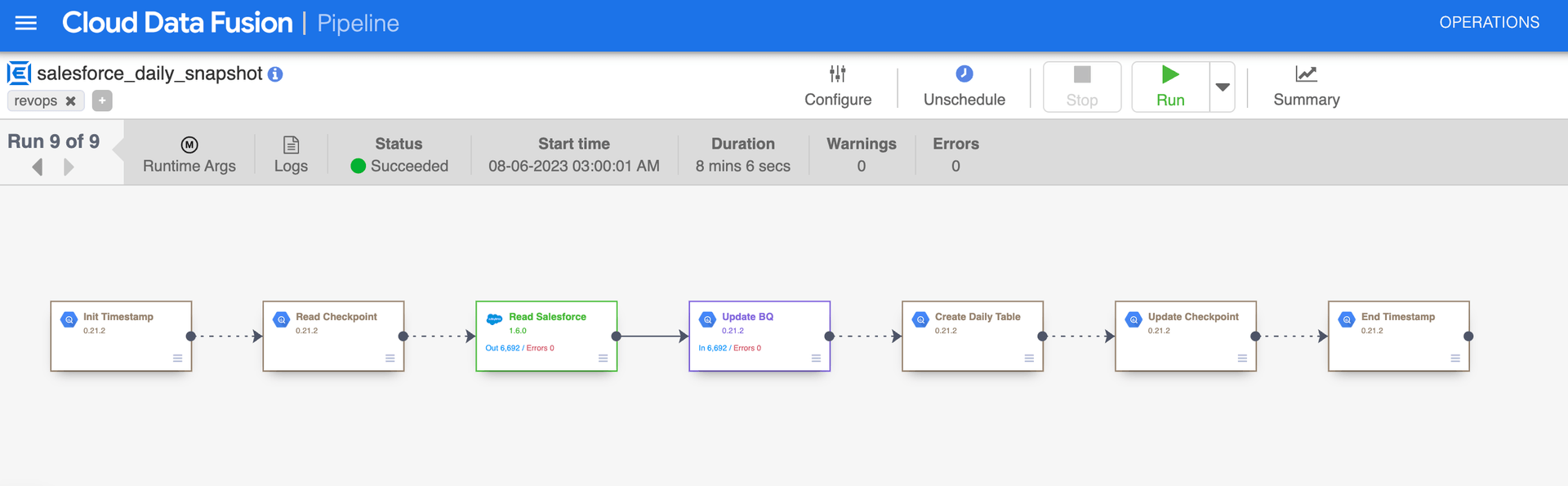
Our working Cloud Data Fusion pipeline which reads from Salesforce and creates daily snapshot tables in BigQuery.
Doing so results in the pipeline above where Step 3 (green) authenticates and reads from Salesforce and Step 4 (purple) dumps the data into BigQuery. We modified the pipeline definition to use our Salesforce credentials (be sure to append the security token to the user password) and added Step 5 which copies data into daily BigQuery tables. We struggled a bit with GCP permissions where the data fusion instance required permission to read and write to BigQuery. Regardless, our pipeline was up and running relatively quickly where data was flowing from Salesforce into BigQuery.
SQL Queries
Now to the SQL that makes this pipeline sing. The technique here is to use BigQuery wildcard tables for the daily snapshot. Each day, the CDF pipeline creates a new table named after one of the Salesforce objects we are getting, for example Opportunity. Step 5 in the pipeline then creates a table specifically for the current day, for example Opportunity_20230809 and dumps the data from Opportunity in there. The key to this query is the use of a variable to define the table name and then EXECUTE IMMEDIATE to create daily tables using those variables. A snippet of this query is shown below. It's necessary to delete the original table afterwards to get ready for the next pipeline run in 24 hours.
The simplified query used to create daily snapshots. This query runs inside the CDF pipeline.
Multiple days of this sequence results in the tables below, where each Salesforce object is grouped together via BigQuery wildcard tables.
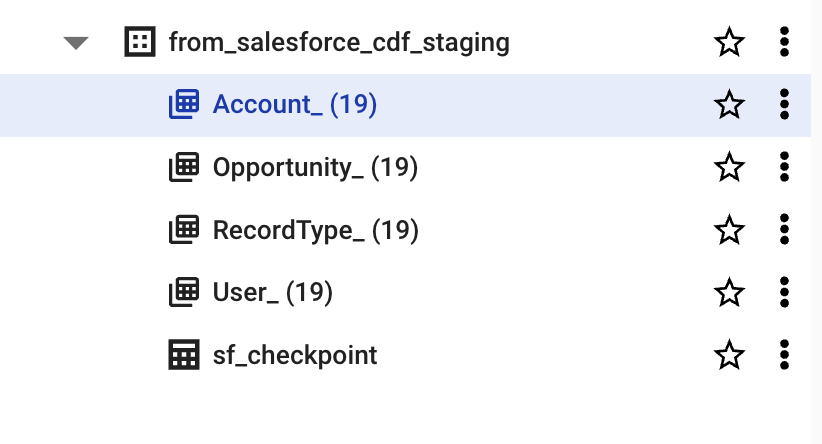
BigQuery wildcard tables containing Salesforce export data for 19 days.
However this is raw data, and querying these tables involves a lot of Salesforce specific knowledge and nomenclature. The next step is to load data from these tables each day into one clean table where each deal (Opportunity) for each day is represented as a row. The end goal is to query this table using WHERE date='2021-08-09' and return all the deals for that day.
The query used to create the derived table which runs in Hex.
The query above consists of multiple independent queries that transform raw Salesforce data and join the results together on the Opportunity.Id field. This query makes use of the wildcard tables functionality via the WHERE _TABLE_SUFFIX = snapshot_time statement. Snapshot time is just the current time formatted in the way that BigQuery wildcard tables expect (e.g. 20230809).

Variables in our Hex notebook used to get the current time as well as regenerate older days if needed.
This query executes 30 minutes after the CDF pipeline completes as a scheduled run in Hex. We elected to have this query in Hex because we found it was much easier to change and regenerate our derived table in Hex than by modifying the CDF pipeline. In the screenshot above you can see the technique we have for regenerating old data if needed using timestamp_sub, which happened several times as we were debugging this setup and finalizing what data we wanted to capture.
Difficulties and Cost Optimization
We did encounter a few hiccups with this setup. With Salesforce authentication, we are using a user and password along with a security token. Our Salesforce instance resets user passwords every so often and when this happens the daily snapshotting breaks.
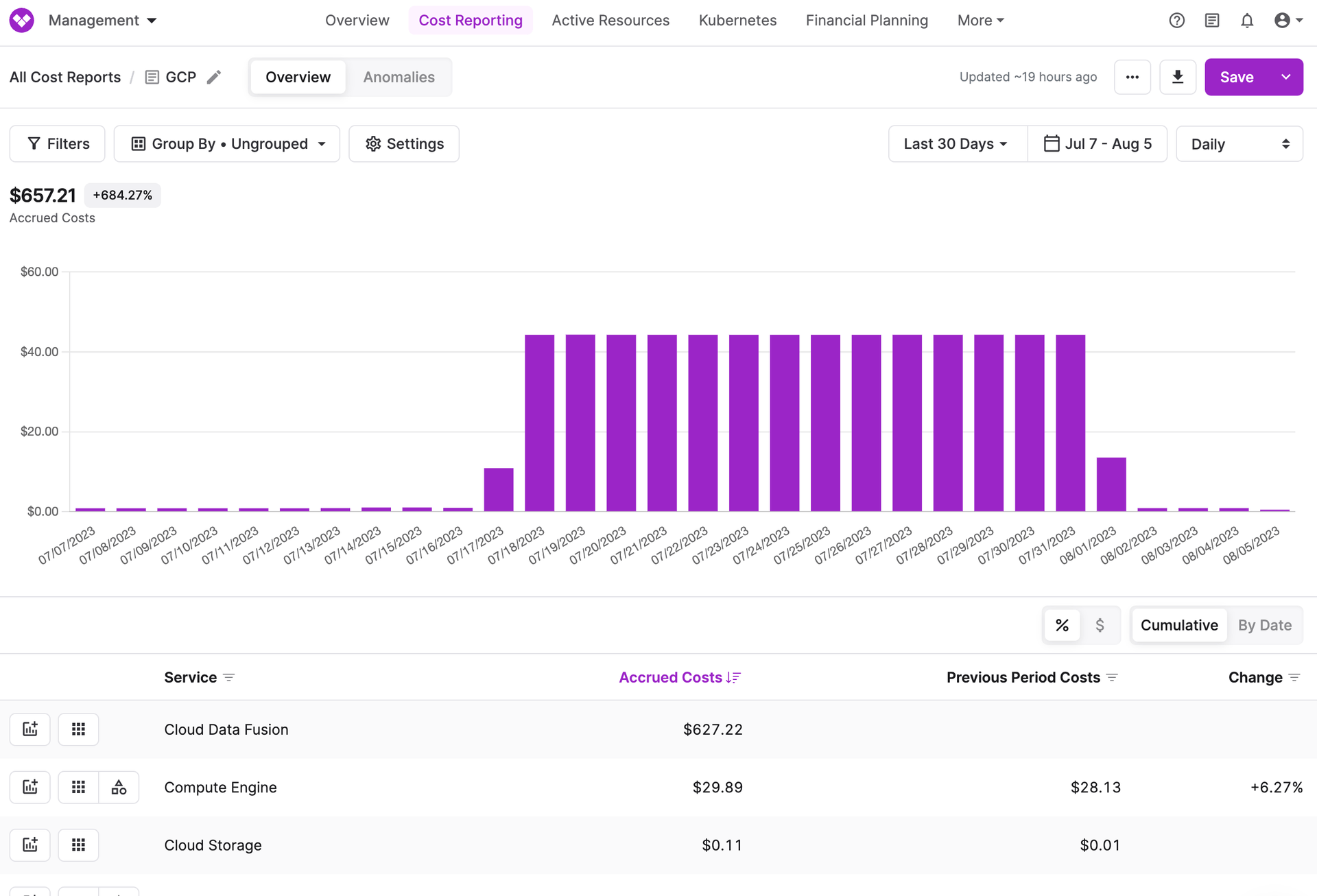
Examining GCP costs in Vantage.
A second challenge was cost optimizing Google Cloud Data Fusion. When we first turned the pipeline on, the instance it ran on stayed live for 24 hours even though the snapshotting only ran for a few minutes every day. This generated $42 in cost per day which we discovered using Vantage. By turning on Autoscaling for CDF we were able to drop the cost back down to cents per day.
Google Cloud is Made for Data
In our recent Q2 Cloud Cost Report we noted how BigQuery and other data services on Google Cloud were driving adoption of overall compute and storage services. That is exactly what happened to us with this setup. We wanted to use BigQuery and in order to get our data into BigQuery we deployed additional Google Cloud services which drove compute and storage spend, in the process solving a business reporting problem which can inform our sales and marketing efforts going forward.
Addendum: Change Schema Capture
One concern that comes up with this is "what if I add a new field to Salesforce?". The CDF pipeline is dumping all fields from the specified objects into BigQuery and the BigQuery wildcard tables documentation stresses that the schema of the tables must be the same. In practice we found this to not actually be true, which is a very nice property. When new fields are added, they are simply picked up and exist in the raw tables going forward. When we want to add them to the derived table, we can modify the second query (add another join) to capture them.
Sign up for a free trial.
Get started with tracking your cloud costs.



