How We Built a Standalone Kubernetes Cost-Monitoring Agent
We built a Kubernetes cost-monitoring solution to eliminate unnecessary complexities and dependencies, support increased scaling, and provide better resource utilization.

The Unix Philosophy is a guiding principle that advocates for simplicity, modularity, and tools that "do one thing and do it well." In the spirit of self-sufficiency, we set out to redefine how Vantage supports Kubernetes cost ingestion and monitoring. Here, we'll discuss our journey to build a standalone Kubernetes cost-monitoring agent.
By developing the Vantage agent, we've achieved remarkable efficiency gains. On some of our largest deployments to date, the agent consumes 95% less vCPU as well as 97% less memory (99% less vCPU and 97.9% less memory at steady state) than previous integrations. Like the ethos of the Unix Philosophy, we built a solution that eliminates unnecessary complexities and dependencies, as well as supports increased scaling and better resource utilization.
The Journey: From Complexity to Simplicity
Kubernetes orchestrates containerized workloads across clusters, which results in complex resource usage patterns. Kubernetes cost monitoring is essential to optimize resource allocation and ensure efficient use of cloud resources. Our customers use Kubernetes cost reporting to quickly identify cost outliers and make better decisions about aligning infrastructure expenses with business objectives. For each iteration of our Kubernetes integration, our primary goal was to provide clear visibility into these complex costs.

October 2021
Container Insights
We launched an initial Kubernetes cost integration that used Container Insights. We soon realized that this method provided a limited set of cost data and was restricted to costs calculated per hour. We also found Container Insights was an added expense for customers, as pod-level metrics needed to be stored and queried from CloudWatch.
November 2022
OpenCost
We launched an integration with OpenCost. In May 2023, we added support for Kubernetes efficiency metrics. We started running into issues related to the tedious setup process, as well as the inability to get certain metrics back from the clusters. These issues caused us to develop an alternative integration solution.
November 2023
Vantage Kubernetes Agent
We officially released the Vantage Kubernetes agent. Then, in December 2023, we added additional efficiency reporting functionality that is improved with the agent.
When we initially decided to create the agent, we focused on the following requirements:
- Streamline onboarding with a simplified setup
- Improve scalability and resource utilization
- Get all the metrics we wanted without additional integration steps
Each of these requirements was a result of lessons learned from previous integrations.
OpenCost Architecture
OpenCost is an open-source Cloud Native Computing Foundation project that runs as a daemon in your Kubernetes cluster and calculates the cost of individual pods. The OpenCost architecture relies on Prometheus, which is responsible for doing the actual scraping of the nodes within the cluster to generate container usage data.
The biggest challenge with the OpenCost integration was the setup process. Data was available only within the cluster, and we needed to get the data out of the cluster to interact with Vantage. So, in addition to the Prometheus deployed within the cluster, an intermediary AWS Managed Service for Prometheus workspace was required for every cluster to push its data to. Customers had to deploy the managed Prometheus workspace outside the cluster and configure OpenCost to export data via the in-cluster Prometheus (see the diagram below). This process added a lot of complexity, especially for customers without an in-cluster Prometheus already set up.
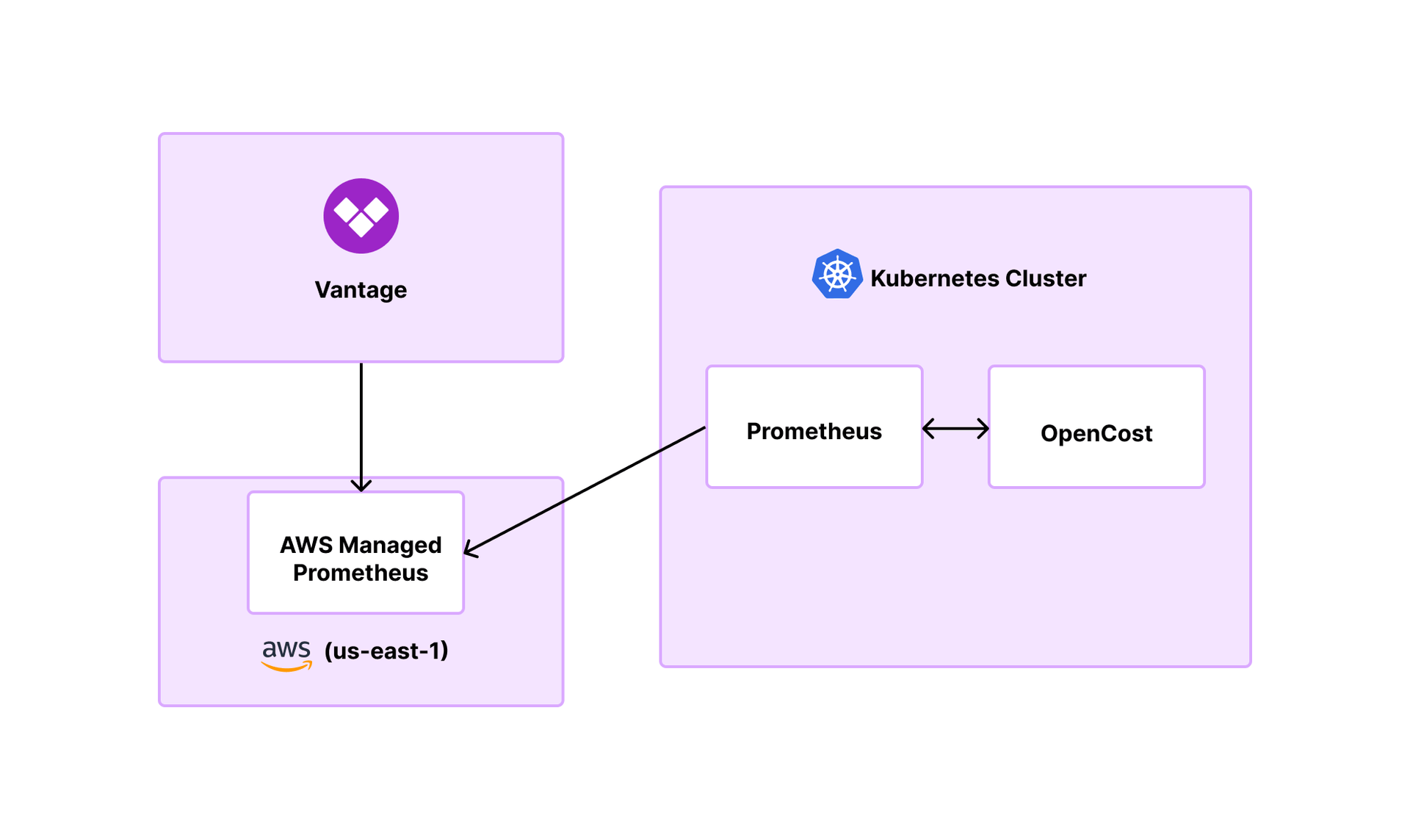
Scaling posed several challenges for us. Larger customers managing hundreds—or even thousands—of nodes in their cluster encountered difficulties with Prometheus scalability. Prometheus faced scalability challenges because its vertical scaling capabilities were limited in handling the data retention demands essential for OpenCost's functionality. For these customers, we had to make critical decisions: either figure out how to scale Prometheus to align with their cluster’s needs, or they may need to explore alternative solutions. Scaling Prometheus for larger clusters, as it turns out, is highly dependent on individual customer setups, what resources they have at their disposal, and whether Prometheus is being used as a shared service or only for OpenCost.
Another issue we ran into was the inability to get certain data we wanted from the setup. For example, a common request was to see idle container stats, which we had trouble obtaining from this setup. Namespace annotations were another common request that we were unable to get with this integration. While alternatives like kube-state-metrics exist, these services would require even more customer configuration for us to then extract the metadata. We attempted to contribute to the upstream OpenCost branch, but after not hearing back, we decided it would make more sense to focus our efforts on creating an integration that gave us the exact metrics we were looking for and could scale as needed.
Building the Vantage Kubernetes Agent
The top priority when building the agent was to remove the intermediary Prometheus requirement, as well as the use of Prometheus within the cluster. Once we removed these requirements, we could effectively scale better and have much shorter implementation times. The agent draws inspiration from metrics-server and uses similar principles and libraries. As a Docker container that’s deployed into each cluster, the agent talks to the kube-apiserver to get a list of nodes and other associated metadata, as well as what PersistentVolumes (PV) are available. These metrics are essential to track the origin of costs within the cluster.
Every minute, the agent scrapes all the nodes provided by the kube-apiserver. The node exports data via the /metrics/resource kubelet endpoint on the node itself. The agent collects data from these sources. Metrics are accounted for at the container level, which are then aggregated up to the pod. At the start of every hour, the agent calls the Vantage API and reports the last hour’s worth of data. The API responds with a place to upload the data. The agent itself does not directly send the data to the Vantage API; instead, it redirects the agent with a pre-signed URL to write to Amazon S3 (see image below). This way, Vantage does not act as an intermediary for S3. The S3 bucket is a Vantage bucket and does not require customer configuration.
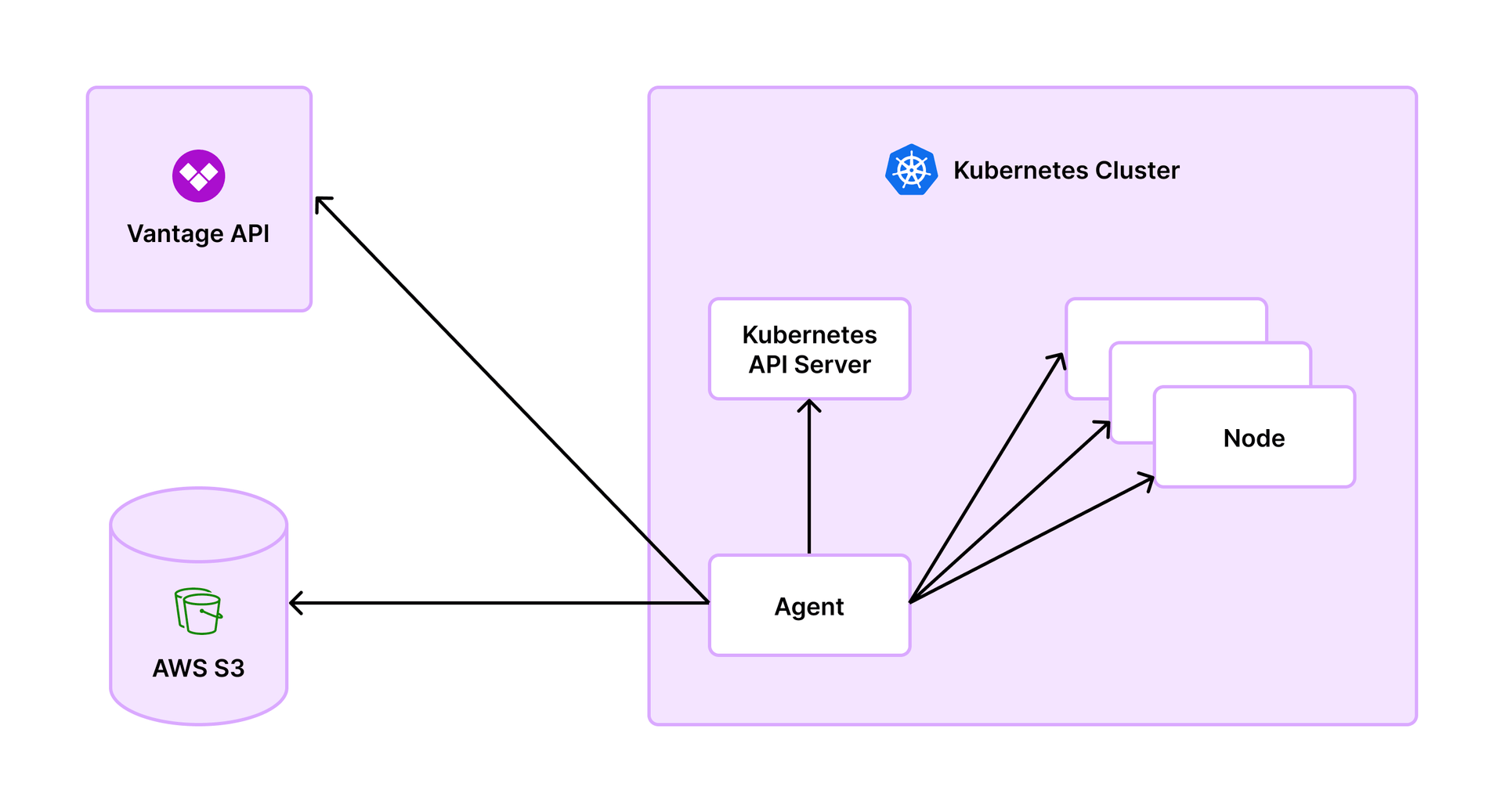
This architecture differs from the OpenCost setup, which used Prometheus to see what resources pods were consuming. After the Vantage agent records data for one hour, it then reports the data to Vantage and discards it. The agent has no API or UI. It’s a completely standalone agent, and we don’t need to store any historical data.
By default, the agent is deployed as a StatefulSet, which means the agent has an associated PV that records the last time the agent reported to the kube-apiserver. If the agent is restarted, the stored data allows it to determine if the previous reporting window was accounted for, providing both reporting and data consistency. The PV also reports a snapshot of the data it’s holding in memory. This data includes metadata for the cluster as well as periodic usage data. If the agent crashes, it can then restart, and instead of losing an hour’s worth of data, it loses only the last few minutes of data.
Streamlining Setup
One of the biggest successes with the agent is the overall simplicity of setup. Customers now need to only add the Vantage Kubernetes agent Helm chart to their local repository and then deploy it to each cluster. The only real deployment requirement is a Vantage API key and a cluster identifier—no more Prometheus! There are several configuration values—like collecting annotations and namespace labels—that customers can adjust for their deployment.
Previously, it could take up to a month, or more, for larger customers to get OpenCost deployed because of their specific configuration and the need to tune scaling until we saw consistent data returned. With the agent, those same deployments worked within minutes.
Improving Scalability and Resource Utilization
So, how exactly does the agent work to solve our scaling and resource utilization problems? Some of the early decisions we made around creating an agent were based on detailed benchmarking. To assess the agent's performance under different scenarios, we conducted the below tests. The observations that came out of these tests gave us confidence that the agent could appropriately scale and use fewer resources than the previous integrations.
Benchmark: Bulk Container Metrics
The BenchmarkBulkContainerMetrics synthetic benchmark simulates the memory usage for container metrics over a minute per container in a large-cluster scenario (e.g., 1,500 nodes x 50 pods per node x 10 containers per pod = 750,000 containers). This benchmark provided insights into potential memory requirements.
The observed outcome was approximately 8GB of memory usage, offering a reasonable estimate for larger-cluster scenarios. In general, we wouldn’t expect to see clusters of this size (i.e., density isn't that typically high, containers per pod isn't typically this high, and pods don't typically stick around for the full hour), but these estimates showed what it was like to store metrics in memory.
Benchmark: Individual Container Metrics
BenchmarkContainerMetric and BenchmarkAggregate are both components of BenchmarkBulkContainerMetrics to help highlight the resource usage of just storing the data for a single container for that same window and then aggregating that data.
In this worst-case scenario, where the container is present for all data points, the observed overhead of aggregating the data we’re storing is roughly 4,000B (4KB) over the 6,000B (6KB) for storing it.
By extrapolating the single-container metric (10,000B) to a large-scale scenario (750,000 containers), the result of 7.5GB (10,000B x 750,000 containers [1500 x 50 x 10] = 7,500,000,000B) closely aligns with the observed outcome of the Bulk Container Metrics benchmark (8GB), indicating a linear growth pattern from 1 container to 750,000 containers.
Default Resource Requirements
To date, the agent has been deployed on clusters ranging from 10 to thousands of nodes. We haven’t needed to add additional performance updates or tuning to the agent’s configuration, which was previously something we had to do with larger cluster sizes. We’ve been able to set default resource requirements for clusters that are 10 to 20 nodes, and these requirements can easily be tuned and adjusted.
The Helm chart has the following default configuration:
Estimates for larger clusters are roughly 1 CPU/1000 nodes and 5MB/node. These estimates vary based on node density, label usage, cluster activity, etc. The agent reaches an approximate steady state after about 75 minutes of consistent uptime, and can then be further tuned accordingly. Generally, we see real-world usage is even lower than the recommended values.
Vantage Agent vs. OpenCost
In the past, for some of the largest clusters we worked with (e.g., a cluster with greater than 1,000 nodes, with over 25,000 pods), we saw requirements of around 6 vCPU and about 180GiB—just for the in-cluster Prometheus. In this same scenario, OpenCost required around 4 vCPU and 8GiB. By comparison, on the same size cluster, the agent consumes only 0.5 vCPU and 5GiB max (steady state is 0.1 vCPU/4GiB). So not only do customers no longer have to pay for the intermediary Prometheus (which was about 1% of a customer’s total EKS cluster cost), but the decreased resource utilization plays a huge difference in overall cluster costs that were coming from resource needs for both OpenCost and Prometheus.
Getting the Metrics We Wanted—Without Additional Setup
With the agent’s architecture in place as well as resource utilization and scaling accounted for, our final requirement was to ensure we were meeting our customers’ data needs. Because of the intermediary Prometheus requirement in OpenCost, data previously had to be serialized in a certain way. For example, Prometheus doesn’t allow certain characters on labels (e.g., -). These characters needed to be substituted, and we would get only a normalized version of the labels. While this worked functionally, it didn’t match up with customers’ expectations. The agent, on the other hand, directly retrieves labels from the kube-apiserver, resulting in more precise data.
In addition, we were previously unable to associate a pod with running on a discounted node. Vantage uses existing Cost and Usage Report (CUR) data to price nodes per hour, based on the existing pricing that we already have for a customer’s cloud integration, which includes discounts. For example, if a customer is already covered by Savings Plans or Reserved Instances, those savings are reflected in the container cost as well while running on a discounted node.
One final consideration was to ensure that the agent was truly Kubernetes-centric and could support integrations across any cloud provider. Because Vantage uses underlying cost data from the cloud provider and exports the usage data from the cluster, we can calculate the corresponding pod costs. As long as the cost data for the underlying cluster instances is available in Vantage, it is possible to calculate the corresponding pods’ costs.
Conclusion
The Vantage Kubernetes agent is a truly standalone solution that does one thing and does it well: streamlines Kubernetes cost monitoring with simplicity, efficiency, and precision. Unlike our previous integrations, the agent is free from unnecessary dependencies and complexities. With a quick setup, better resource utilization, and the ability to provide data that aligns with our customers' expectations, the Vantage Kubernetes agent embodies simplicity and efficiency in the world of containerized environments.
Sign up for a free trial.
Get started with tracking your cloud costs.



